機械学習の重要なアイデアをやさしく解説
急速に広がる機械学習の活用は、いくつもの難しい問いを投げかけています。モデルが公平かどうかはどのように見極めればよいのでしょうか。モデルはなぜそのような予測を下すのでしょうか。膨大な量のデータをモデルに投入することには、どんなプライバシー上の影響があるのでしょうか。
この連載形式のインタラクティブなエッセイは、そうした重要な概念を順を追って案内します。
original English contents are available at: https://pair.withgoogle.com/explorables/


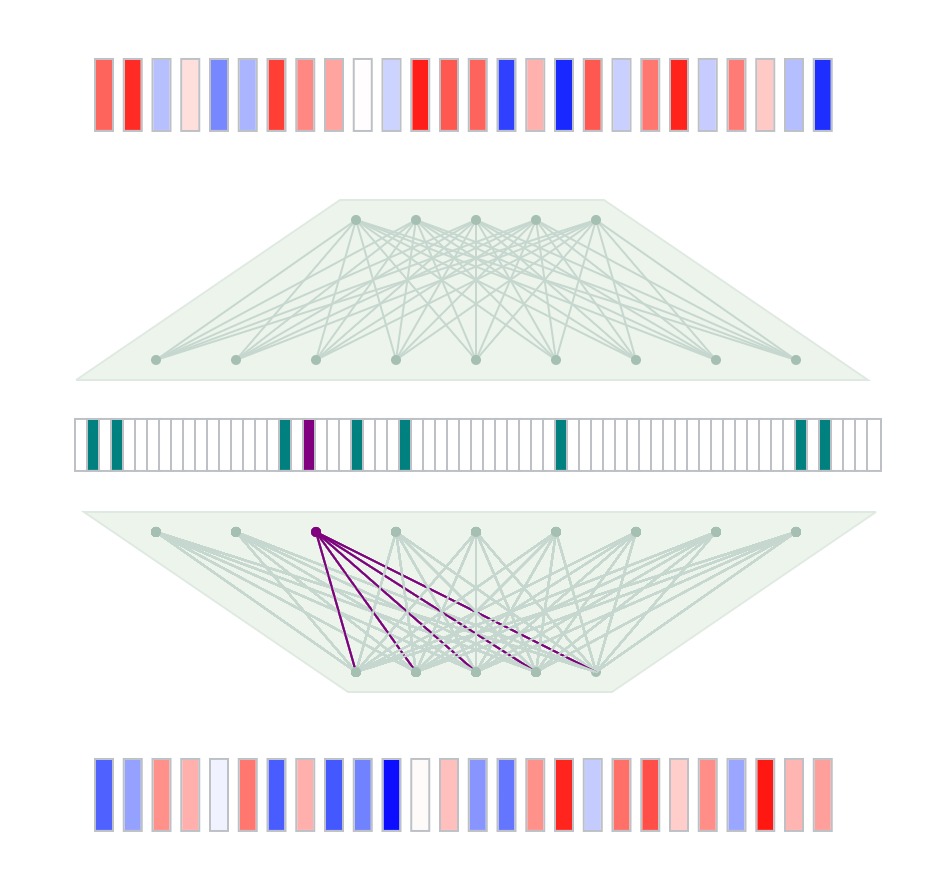
スパース・オートエンコーダを使って、大規模言語モデル内部の表現を読み解く
Sparse Autoencoders
スパース・オートエンコーダを使って、大規模言語モデル内部の表現を読み解く手法を紹介します(英語)。

大規模言語モデルは内部機構を説明できるのか?
Can Large Language Models Explain Their Internal Mechanisms?
LLMの潜在表現を解き明かすための検査フレームワークであるPatchscopesを、LLMとともに紹介します。


自信満々に誤るモデルから謙虚なアンサンブルへ
From Confidently Incorrect Models to Humble Ensembles
分布外のデータに遭遇すると、機械学習モデルが自信を持って誤った予測をすることがあります。モデルのアンサンブルは、誤差を平均化することでより良い予測を行えます。
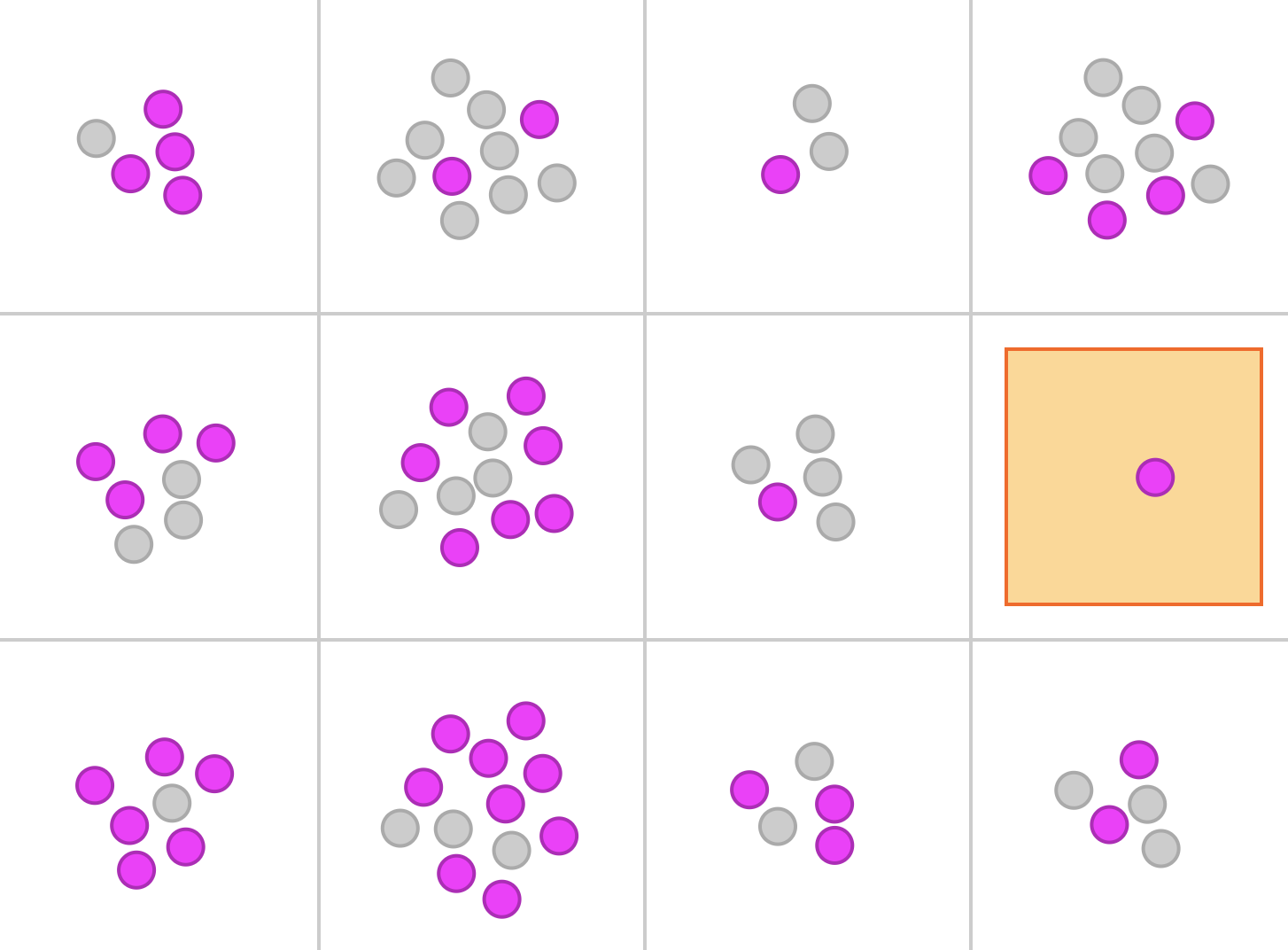
機微情報を集める方法
How randomized response can help collect sensitive information responsibly
膨大なデータセットと高速なコンピュータの登場により、人々のプライバシーを意図せず侵害することなく、機微情報を収集・研究することが難しくなっています。

なぜモデルはデータを漏えいさせるのか
Why Some Models Leak Data
機械学習モデルは大量のデータを使用します。その中には機微なデータも含まれることがあります。適切に学習されないと、そうしたデータが意図せず漏えいすることがあります。

差分プライバシーと公平性の両立は可能か?
Can a Model Be Differentially Private and Fair?
差分プライバシーを用いてモデルを学習すると、機密データが意図せず漏えいするのを防げますが、思わぬ副作用として、代表性の低いサブグループに対する精度が下がることがあります。

フェデレーテッド・ラーニング
How Federated Learning Protects Privacy
ほとんどの機械学習モデルは、膨大なデータを中央サーバーに集めて訓練されています。フェデレーテッド・ラーニングを使えば、ユーザーの生データをデバイスから外に出さずにモデルを訓練できます。

モデルの予測は確率なのか?
Are Model Predictions Probabilities?
機械学習モデルは不確実性をモデルスコアとして表現しますが、キャリブレーションを通じてこれらのスコアを確率に変換することで、より効果的な意思決定が可能になります。

Saliencyで意図しないバイアスを探す
Searching for Unintended Biases With Saliency
機械学習モデルは訓練データの疑似相関から学習することがあります。モデルがどのように予測するのかを理解しようとすることで、欠陥のあるモデルを発見する手がかりが得られます。


多様性を測る
Measuring Diversity
歴史的な不平等を反映した検索結果は、ステレオタイプを強め、特定の人々が過小に扱われ続ける原因になり得ます。データセットの多様性を丁寧に測定することで、そのような問題の軽減に役立ちます。

公平性を測る
Measuring Fairness
精度を評価する方法は一つではありません。どのようにモデルを構築しても、それぞれの指標における精度は、対象となる人々のグループによって必ず差が生じます。
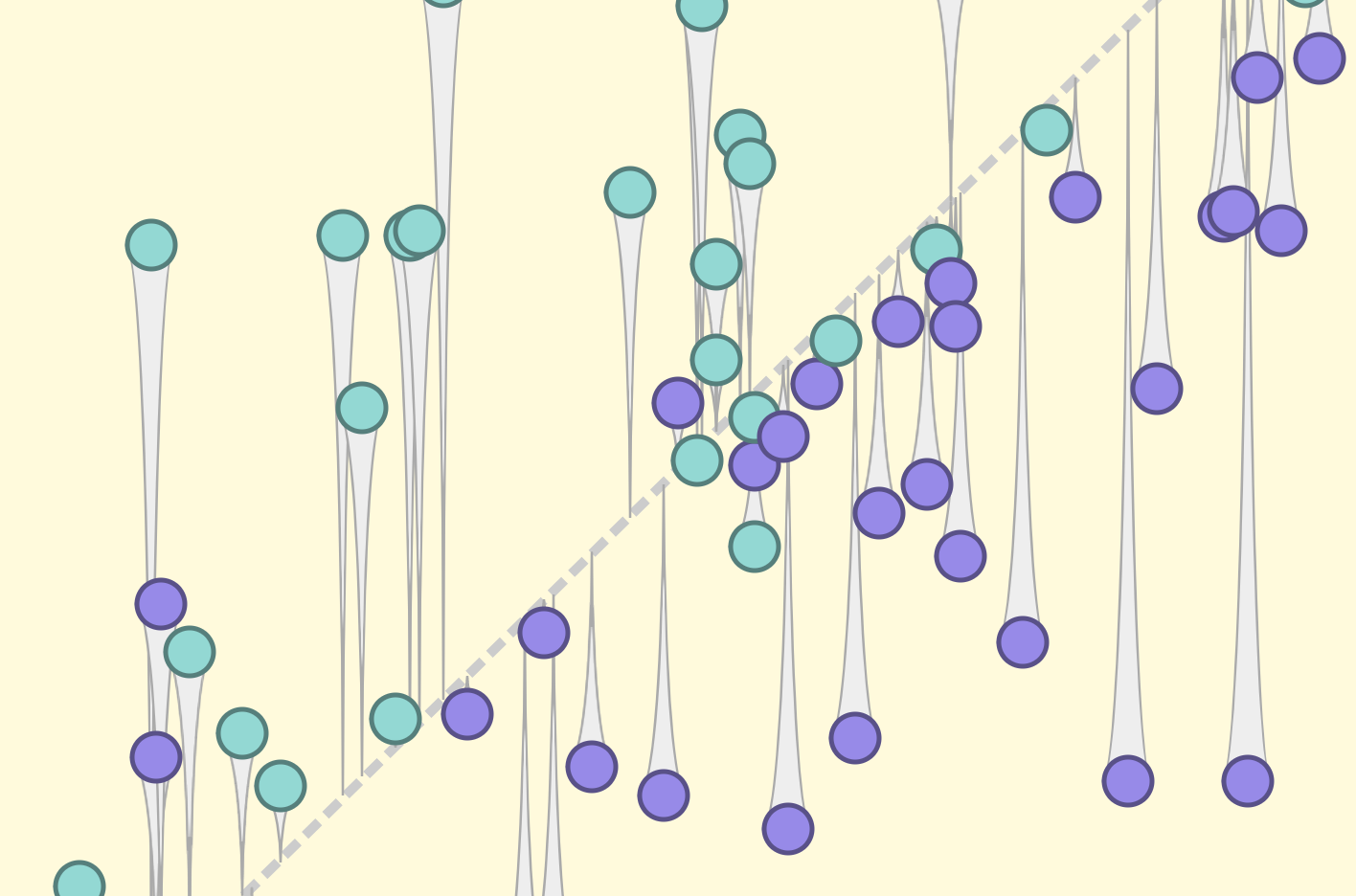
隠れたバイアス
Hidden Bias
現実世界のデータで学習したモデルには、現実世界の偏りがそのまま刻まれることがあります。保護されるべき属性の情報を隠しても、必ずしも問題が解決するわけではなく、場合によっては状況を悪化させることさえあります。
